Mechanism design is a broad and somewhat abstract part of Economics that one rarely hears about in day to day conversation. At its core it is about how the systems around us map preferences onto outcomes. Before one looks more into mechanism design it can seem like quite a fringe part of Economics, many of the proposals it comes up with seem overly complicated and esoteric. Even if one doesn’t take up many of the proposals it comes up with though, I believe being aware of what mechanism design is and what it deals with helps one take notice of the systems that one often ignores as invisible that actually shape the world around us.
That is somewhat abstract so below we’re going to have a concrete look at a problem and how some different mechanisms deal with it. In the below example we take a set of preferences π run them through a mechanism 𝜑 and get an outcome μ. In this setting we are looking to find pairs of people who will go out with each other based on their preferences over the other sex.
The preferences of the three men are on the left and of the three women on the right.
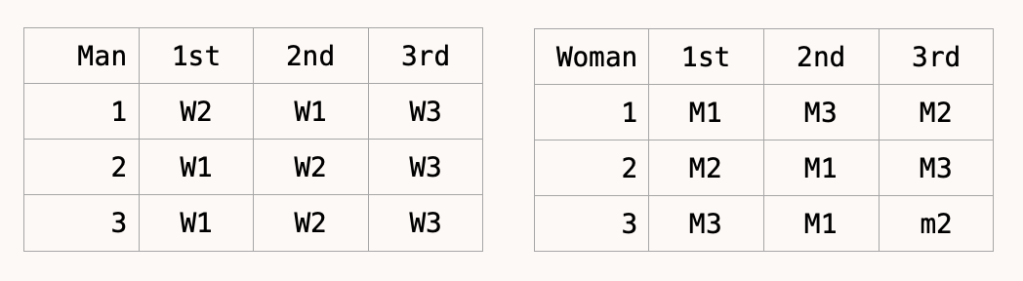
Now consider three different mechanisms to pair up these people.
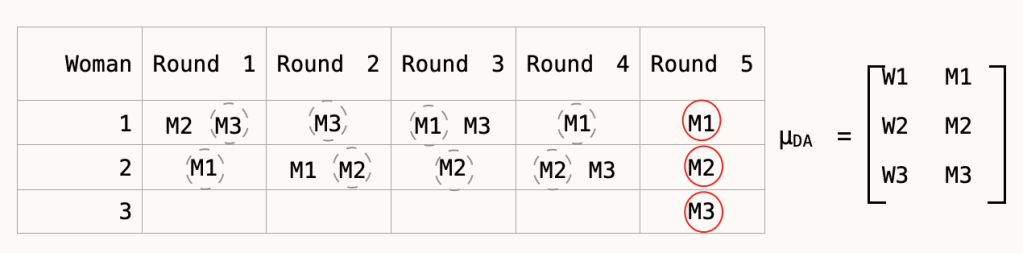
Deferred acceptance: Here each round the men go to the women who is highest on their list of preferences, the women tentatively accepts their favourite option and reject the rest. The next round if you have been tentatively accepted you stay where you are otherwise you move to the woman who is next highest out of your preferences.
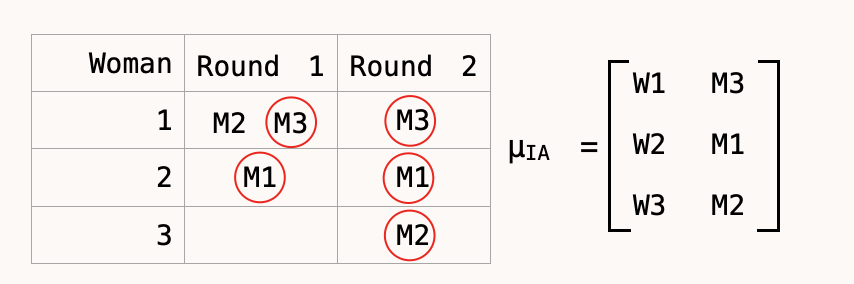
Immediate acceptance. Here a man would go to the woman highest up their preference ordering. If they are the most preferred candidate that approaches the women in that round they will be immediately and irrevocably chosen, if rejected then the next round they go to the women who is highest up their preference rankings who is still available and this continues until all men and woman are in pairs.
Top trading cycle: For this one you can imagine drawing all the men and women on a piece of paper with arrows going between each individual to their most preferred choice. If there is a cycle then all the men get immediately paired up with whichever women they were pointing at in the cycle. If you were pointing at someone who has now been paired up then in the next round you point to the person who ranks highest who is still available.

As you can see no mechanism that we have used gives the same allocation of partners. One question this begs is are any of the allocations better than the others? This question is at the heart of mechanism design, there are certain things you might want an allocation to have and only sometimes will a mechanism give them to you.
Theoretic considerations
The first set of considerations are what I will call ‘theoretical’ considerations. These are properties of a system that you can verify with formal maths or logic. In this case the three most obvious are;
Stability: This means that there is not woman, man pair that would both prefer to be with each other compared to the partner they have been given.
Efficiency: In this example we will take this to mean that you cannot change the partner of any man without making the man they swap with worse off.
Strategy Proofness: This means that the way to have the best chance of getting your actual highest preference is to declare your true preferences. i.e you gain nothing by being tactical in how you present your preferences.
So how do our three mechanisms do?

In Deferred acceptance M1 and M2 could swap and both would end up happier so it is not efficient (W1 and W2 would not however be happier, hence stable).
In Immediate acceptance W2 would prefer M2 to her allocation M1, M2 would also prefer W2 to their allocation of W3 so this is not stable. Also in this case if M2 didn’t report their preferences truthfully and actual said that W2 was their most preferred matching then they would have ended up with W2 rather than W3 and so achieved a better matching so this is not strategy proof.
In the Top trading cycle M3 prefers W1 to his allocation of W3, W1 however also prefers M3 to her allocation of M2 and so they would both be happy to change partner so it is not stable.
We can see that no mechanism has managed to give us all three of these characteristics that one might initially view as all being beneficial. This may seem like an unfortunate situation that these mechanisms weren’t able to overcome, but at least in this setting it is far more serious, you can’t in fact ever obtain all three of these traits. This harks back to Arrow’s impossibility theorem for voting, a set of goals that all seem desirable are to some degree mutually exclusive.
This introduces us to one of the first broad lessons of mechanism design, there are in many cases truly irremovable tradeoffs that one has to make. Even before we have reached any value judgements we have to decide if we value efficiency over stability, strategy proofness over stability etc.
The above are the theoretical considerations that make the most sense to look at in the above example but they are far from the only theoretical considerations one might want to look at. If we look at the birthplace of mechanism design, auctions, it is clear that revenue from different types of auctions is something that one will want to consider. One result that is pretty fun is the ulterior benefits of certain types of strategy proof mechanisms. If we take a first price sealed bid and a second price sealed bid auction then while there is an optimal bid for people to make in both cases that they don’t benefit from deviating from while the two auctions are revenue equivalent, the second price auction actually has your exact utility of an object as your optimal bid. This means that you are able to receive really valuable information whilst at the same time not sacrificing revenue.
In voting there are hosts of other things one might want to look at, some of them are similar or the same as the above considerations but others are different such as not having any dictators who can make the group follow whatever they want it to do.
Normative considerations
Beyond just the theoretical considerations there are clearly many other things one might want to think about when looking at how a mechanism works. One group of these are called normative considerations; value judgements, things like is the outcome fair, is it equitable? Just like with the theoretical considerations it is very likely, and sometimes a necessity, that no mechanism will be able to satisfy all of the normative considerations one wants addressed.
One interesting point is that many theoretical considerations actually have some footing in normative settings. For example, strategy proofness means that agents who have more ability/resources to give to tactics and strategising aren’t able to gain a leg up over those who don’t. This was a major concern in the redesign of the Boston school placement algorithm.[1] If rich families were better able to coordinate and strategise than poorer families then this could lead to an unfair distribution of children. Making the algorithm strategy proof means that families of all abilities to think/plan are on a level playing field.
Similarly stability can be linked to the concept of justified envy. If you have a situation where there are unstable matchings then, to stick with the school example, a student might be annoyed that they aren’t at a school that not only they would prefer to be at but the school would prefer them as well.
Other types of normative considerations are clearly also worth looking at. For example, with the school case, it might be that levels of segregation are of concern and so you want to factor this in when looking at allocations.
One factor to keep in mind is whether the system the mechanism is put in is the right one to even be solving. This was brought up as a potential issue with the Boston School placement mechanism. One of the considerations schools took into consideration to rank students were how far their neighbourhood was from the school itself. While the new mechanism was being designed six different proposals were submitted to redraw the neighbourhood bounds which would have changed which students ended up at which schools. In the end though the walk bounds were kept the same while the allocating mechanism changed.
Now keeping the neighbourhoods may or may not have been the ‘better’ move however this illustrates how one might end up with a situation where the perceived objectivity of a mechanism is substituted for a potentially less objective issue such as neighbourhood boundaries. Just because you are solving one issue doesn’t mean it is necessarily the right one to be solving, as Bryan Caplan calls them you risk committing a type 3 error, getting the right answers to the wrong questions.[2]
Implemental considerations
Another set of considerations which don’t frequently get labeled as a distinct group are what I would call ‘implemental’ considerations. These are the kinds of things that lead Yogi Berra to remark how “in theory theres no difference between theory and practice”.
Mechanism design can often be fairly abstract and in these cases one almost always needs to make some simplifying assumptions to be able to get anywhere. The issue comes that simplifying assumptions should be ones that if relaxed don’t actually materially change the outcome and this is not always the case.
One common implemental consideration is relaxing the idea that the people in your system will be rational. In some situations it might be perfectly reasonable to assume that the agents involved will be able to think through things in a rational way but in others this is a dangerous assumption to make. Rationality can be a pretty hefty bar to overcome, even the most ‘rational’ people have computational constraints that prevent them from what one might call full rationality.[3]
One consideration, which might also be at home in the normative section, is complexity. Some mechanisms can be pretty complex, e.g ones in blockchain. There are two considerations to take into account when it comes to complexity, the first is will people actually be able to use the mechanism. Richard Hasen in his article[4] looking at quadratic voting (QV) mentions that in a scheme he has been involved in to do with allocating credits to be given to political campaigns that they dropped the quadratic aspect because ” most people rolled their eyes when they heard that they needed to compute square roots in order to participate in politics”.
The second is the effect complexity has on transparency. If we return to blockchain then to a reasonable degree as long as the mechanisms work they can operate in a rather black box fashion. This is almost certainly not the case in something like elections. Here a mechanism that is complicated enough to not be understood by most people will almost certainly not be politically acceptable. Or if people are even worried that they wouldn’t vote in their best interests because of some mechanisms then this could be enough to warrant some mechanism not being used.
We also might want to consider the norms of how people act and whether our mechanism aligns with those or if it is vulnerable to them. If we take the case of quadratic voting then one weakness it has is that it is particularly vulnerable to collusion. I won’t go into all the details of QV here because I’m planning to write more about it at some other point but if you really value policy A and I really value policy B then it is our mutual best interest to find each other and divide our votes rather than just vote for the thing we really care about.[5] Other mechanisms such as cumulative voting, while potentially having a weaker theoretical ability to discern intensity of preference may therefore achieve the task better in real world situations.
An interesting point is that with mechanisms to do with blockchain the theoretical and implemental considerations can blur far more than in other settings. If we take voting again, even if the mechanism is a bit complicated creating the infrastructure necessary to map π to μ is not likely to be very complex[6], with blockchain though this infrastructure in many cases is the very thing one is trying to create and so the successful implementation is itself one of the major technical goals.
Mechanisms in the wild
One insight that I want to bring up is one that gets brought up roughly every election cycle, without it necessarily having the words mechanism design used, is the effect different mechanisms would have to the status quo. The real world uses a plethora of mechanisms in decisions ranging from elections, to schools, to kidney transplants. All of these have been created at one point or another an all have, as we saw earlier, irremovable trade offs. It can be worth questioning why certain mechanisms are they way they are and what tradeoffs those mechanisms are making.
Many of the mechanisms we use today might seem rather benign and uncontroversial but if you look at the history of almost any mechanism we use today would have been incredibly radical at one point or another. It is unlikely the mechanisms we use today are the final iteration of where we end up, one fun thought is to consider which ones are most likely to see change in the next few decades or even further out.
Overall I want to get across three things about mechanism design
- There are three types of (sometimes interlinked) considerations: theoretical, normative, implemental.
- One of the recurring themes is that often sets of beneficial goals cannot ever be reached at the same time, contrary to what ones intuition would often suggest.
- We operate in a world that runs on mechanisms designed by others, and as we have seen almost all will involve levels of tradeoffs. Many of these may well not be the best they could be but many also become invisible to most people as just part of the status quo.
[1] For original Boston school placement (BSP) paper: http://cramton.umd.edu/market-design/abdulkadiroglu-sonmez-school-choice.pdf
For normative discussion of BSP: https://scholar.harvard.edu/files/hitzig/files/finalrevision.pdf
[2] to clarify I am not saying this was actually the case in the Boston example just that it can be possible to get overly fond of the legible benefits of a well designed mechanism over less legible problems
[3] if you aren’t convinced by this already I would simply get you to think through this example https://xkcd.com/blue_eyes.html you might be able to figure out the answer but if you were actually asked to talk through the iteratively recursive cycles you’d likely get pretty lost pretty quickly
[5] if you just can’t wait for that then these are two great sources that I’ll be using on QV
https://vitalik.ca/general/2019/12/07/quadratic.html
https://pubsonline.informs.org/doi/10.1287/mnsc.2019.3337
[6] By this I more mean that things like figuring out how many tokens someone has left in a QV setting is not a complicated sum to do instead of meaning something like making secure digital voting which does pose difficult infrastructural issues
